Vector Databases broke down in 3 Levels of Difficulty
Traditional databases answer a well-defined question: does the record matching these criteria exist?
What’s Happening
Okay so Traditional databases answer a well-defined question: does the record matching these criteria exist?
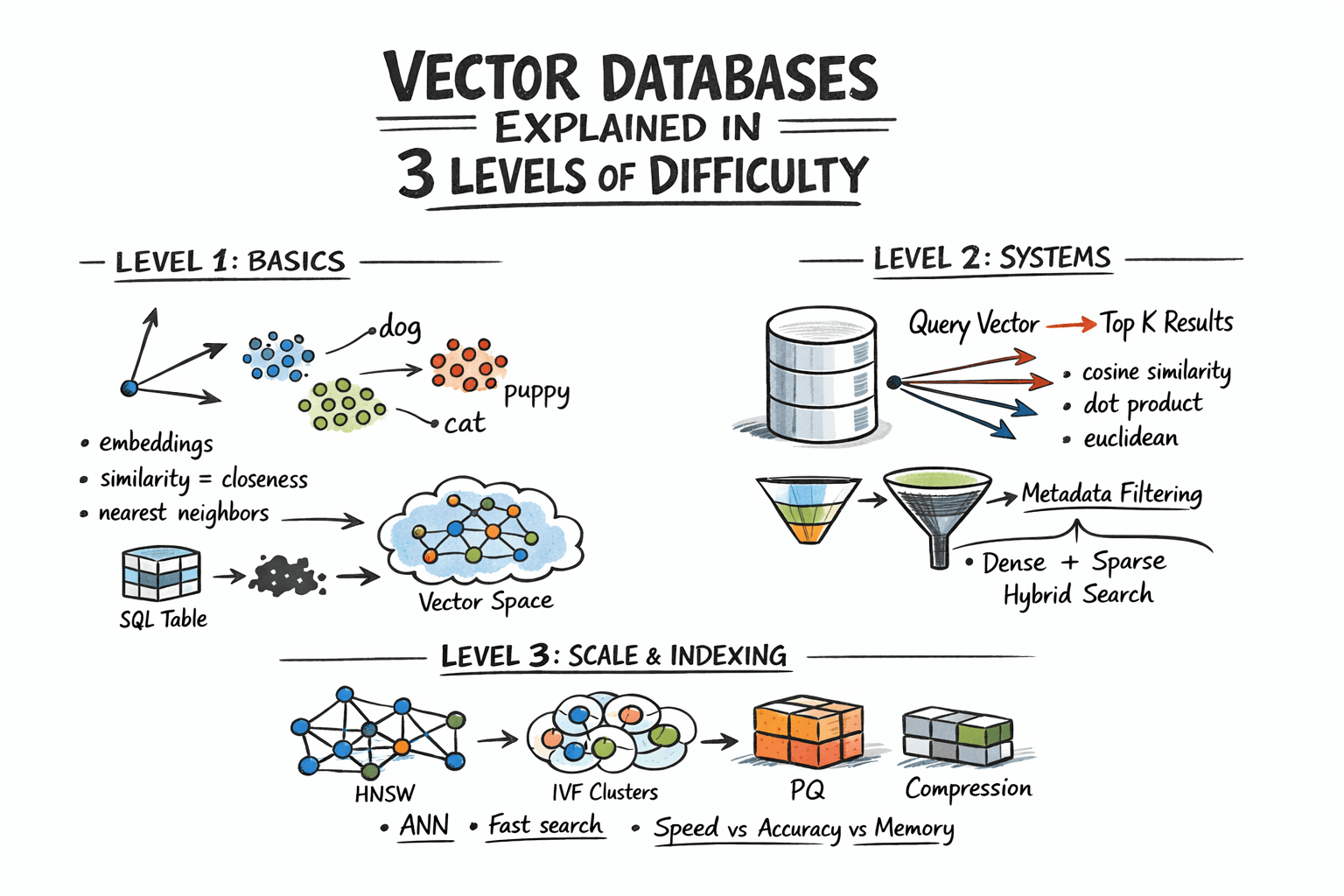
a href=” Vector Databases broke down in 3 Levels of Difficulty By Bala Priya C on in Language Models 0 Post In this article, you will learn how vector databases work, from the basic idea of similarity search to the indexing strategies that make large-grow retrieval practical. Topics we will cover include: How embeddings turn unstructured data into vectors that can be searched by similarity. (shocking, we know)
How vector databases support nearest neighbor search, metadata filtering, and hybrid retrieval.
The Details
How indexing techniques such as HNSW, IVF, and PQ help vector search grow in production. Vector Databases broke down in 3 Levels of Difficulty Image by Author Introduction Traditional databases answer a well-defined question: does the record matching these criteria exist?
Vector databases answer a different one: which records are most similar to this? This shift matters because a huge class of modern data documents, images, user behavior, audio cannot be searched .
Why This Matters
So the right query is not find this, but find what is close to this. Embedding models make this possible content into vectors, where geometric proximity corresponds to semantic similarity. The problem, but, is grow.
This adds to the ongoing AI race that’s captivating the tech world.
The Bottom Line
Vector databases solve this with approximate nearest neighbor algorithms that skip the vast majority of candidates and still return results nearly identical to an exhaustive search, at a fraction of the cost. This article explains how that works at three levels: the core similarity problem and what vectors enable, how production systems store and query embeddings with filtering and hybrid search, and finally the indexing algorithms and architecture decisions that make it all work at grow.
Thoughts? Drop them below.
Daily briefing
Get the next useful briefing
If this story was worth your time, the next one should be too. Get the daily briefing in one clean email.
Reader reaction


