NVIDIA Researchers Introduce KVTC Transform Coding Pipeli...
Serving Large Language Models (LLMs) at grow is a massive engineering challenge because of Key-Value (KV) cache management.
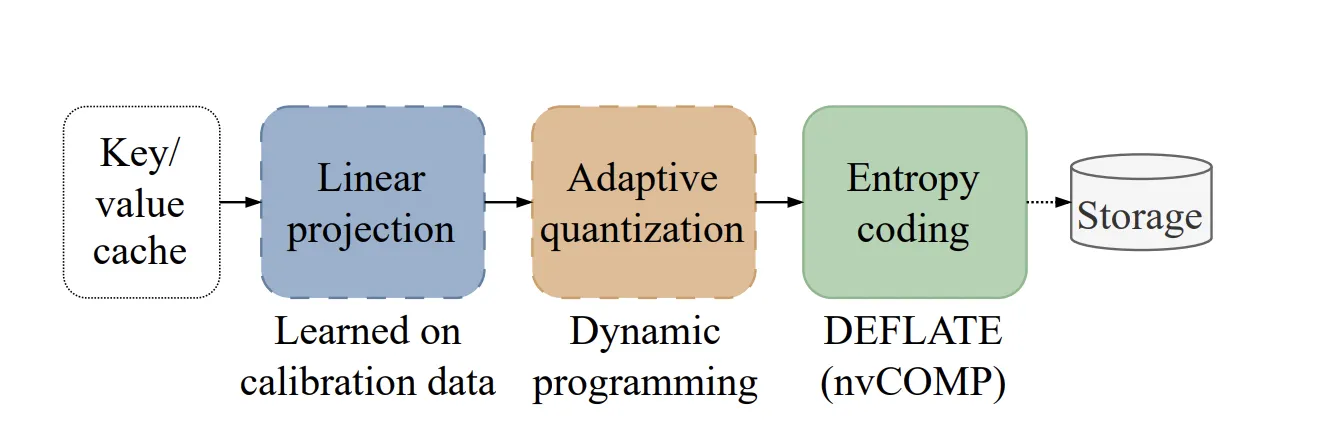
What’s Happening
Alright so Serving Large Language Models (LLMs) at grow is a massive engineering challenge because of Key-Value (KV) cache management.
As models grow in size and reasoning capability, the KV cache footprint increases and becomes a major bottleneck for throughput and latency. (plot twist fr)
For modern Transformers, this cache can occupy multiple gigabytes.
Why This Matters
As AI capabilities expand, we’re seeing more announcements like this reshape the industry.
This adds to the ongoing AI race that’s captivating the tech world.
The Bottom Line
This story is still developing, and we’ll keep you updated as more info drops.
What do you think about all this?
Daily briefing
Get the next useful briefing
If this story was worth your time, the next one should be too. Get the daily briefing in one clean email.
Reader reaction


