NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Met...
As context lengths move into tens and hundreds of thousands of tokens, the key value cache in transformer decoders becomes a primary depl...
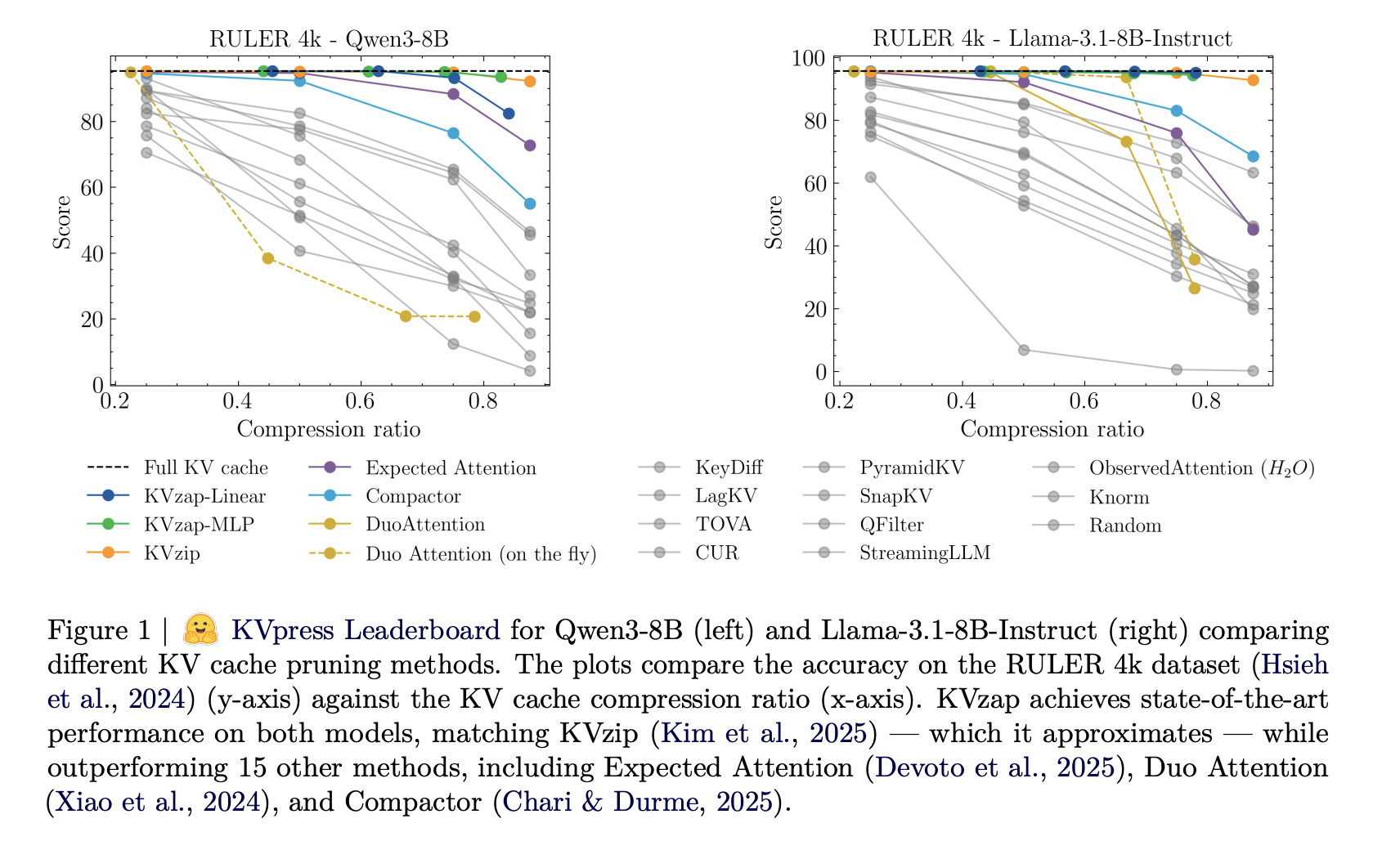
What’s Happening
Listen up: As context lengths move into tens and hundreds of thousands of tokens, the key value cache in transformer decoders becomes a primary deployment bottleneck.
The cache stores keys and values for every layer and head with shape (2, L, H, T, D). (plot twist fr)
For a vanilla transformer such as Llama1-65B, the cache reaches about 335 GB [] The post NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x Compression appeared first on MarkTechPost.
Why This Matters
As AI capabilities expand, we’re seeing more announcements like this reshape the industry.
This adds to the ongoing AI race that’s captivating the tech world.
The Bottom Line
This story is still developing, and we’ll keep you updated as more info drops.
How do you feel about this development?
Daily briefing
Get the next useful briefing
If this story was worth your time, the next one should be too. Get the daily briefing in one clean email.
Reader reaction


