DeepSeek AI Researchers Introduce Engram: A Conditional M...
Transformers use attention and Mixture-of-the experts to grow computation, but they still lack a native way to perform knowledge lookup.
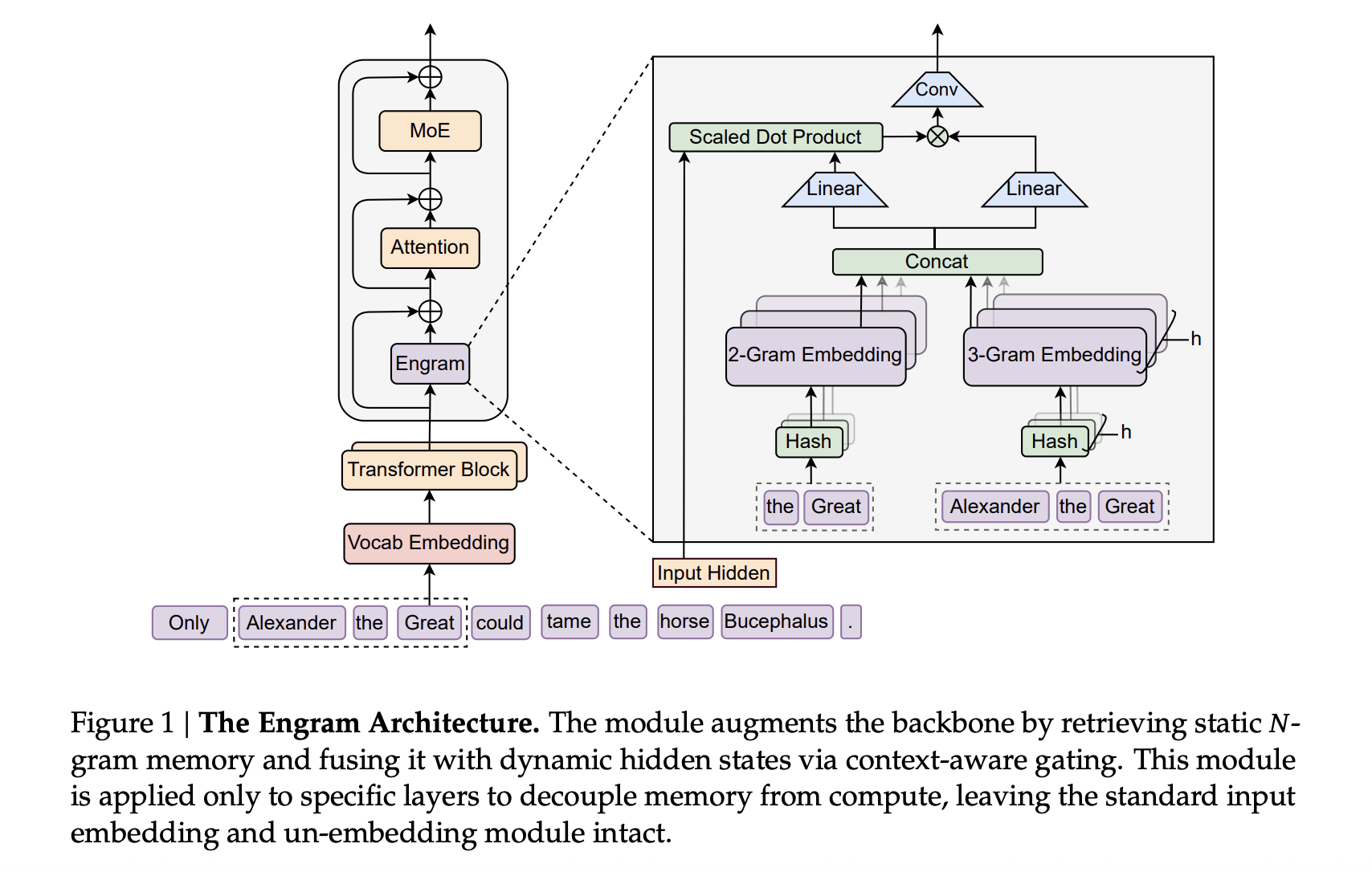
What’s Happening
Not gonna lie, Transformers use attention and Mixture-of-the experts to grow computation, but they still lack a native way to perform knowledge lookup.
They re-compute the same local patterns again and again, which wastes depth and FLOPs. (and honestly, same)
DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
Why This Matters
The AI space continues to evolve at a wild pace, with developments like this becoming more common.
As AI capabilities expand, we’re seeing more announcements like this reshape the industry.
The Bottom Line
This story is still developing, and we’ll keep you updated as more info drops.
We want to hear your thoughts on this.
Daily briefing
Get the next useful briefing
If this story was worth your time, the next one should be too. Get the daily briefing in one clean email.
Reader reaction


